خیلی خب! در قسمت قبل (یعنی این پست) با "Hash" کردن یا دَرهم نگاری آشنا شدیم و فهمیدیم که هَش کردن یعنی اختصاص یک رشته ی با طول ثابت به یک ورودی دلخواه، با این شروط که:
- از روی مقدار هش مقدار ورودی قابل تولید نباشد.
- احتمال این که به ازای دو ورودی مختلف، یک خروجی تولید شود به قدری کم باشد که قابل چشم پوشی باشد.
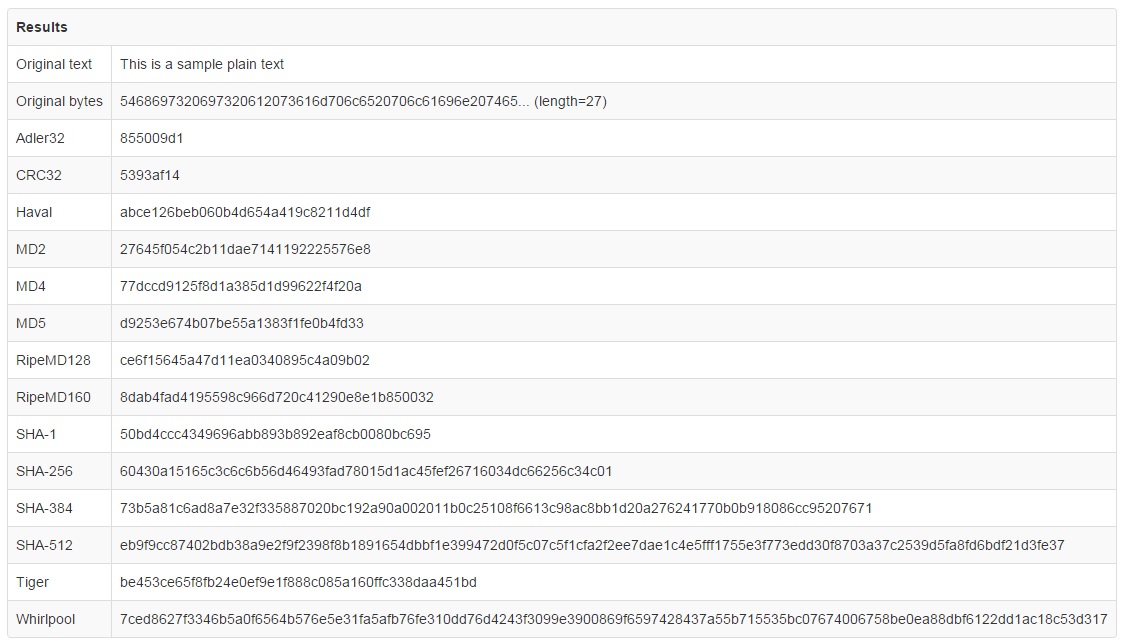
همچنین فهمیدیم که الگوریتم های Hash کردن، کلید یا رمز ندارند و همه چیز صرفا یک الگوریتم است که تنها ورودی آن داده ی مورد نیاز برای Hash شدن است. برای عملی تر شدن توضیحات، می توانید با مراجعه به این سایت یا این سایت عبارت های مورد نظر خود را با چند الگوریتم مشهور دَرهم نگاری هش کنید. به هر حال من قبلا این کار را برای عبارت "This is a sample plain text" انجام داده ام و نتیجه را برای شما داخل عکس زیر آماده کرده ام:
و اما:
قسمت 2: Encoding/Decoding
معرفی فرایند:
چیزی که در این پست با آن آشنا میشویم، Encoding و Decoding است. طبق نوشتهی ویکیپیدا، Encoding به فرایند جایگزینی کاراکترها و رشته با کاراکترها و رشته های دیگری است که انتقال یا ذخیرهی آنها برای یک سیستم بهینه تر باشد و همچنین، عمل Decoding تغییر دوباره ی فرمت این کاراکترهای Encode شده به فُرم اولیهی آنها میباشد.
اما اگر بخواهیم به زبان ساده تر بیان کنیم، Encode کردن و Decode کردن مشابه فرایند ترجمه ی یک متن از یک زبان به زبان دیگر است. یعنی همانطور که در دنیای واقعی میتوان یک متن فارسی را به راحتی به زبان های مختلف دیگر ترجمه کرد و بعد دوباره به متن اصلی بازگرداند، در دنیای رایانهها هم میتوان یک داده را به فرمت های مختلف ترجمه یا در اصطلاح Encode کرد و بعد دوباره به فرمت اولیه بازگرداند یا اصطلاحا Decode کرد و باز همانطور که در دنیای واقعی اگر زبان مقصد معادلی برای قسمتی از متن اصلی نداشته باشد، ترجمه ی آن قسمت امکان پذیر نیست، در دنیای رایانه هم گاها، Encode کردن یک داده از یک فرمت به فرمت دیگر، به خاطر پشتیبانی نکردن فرمت مقصد از قسمتی از داده ی ورودی، با شکست مواجه میشود. (یا به داده هایی غیر قابل بازگشت تبدیل می شوند.)
بنابراین، با توجه به مثال ارائه شده، Encode و Decode کردن تغییر فرمت(نحوهی نمایش) یک متن/داده است به گونه ای که:
- قابل بازگشت باشد.
- هر شخصی بدون نیاز به هیچگونه کلید یا رمزی و تنها با اطلاع از ساختار آن فرمت ها، قادر به انجام آن باشد.
از آنجا که با ارائه شدن هر محصول یا تکنولوژی ای، معمولا یک فرمت بهینه برای آن سیستم ارائه میشد، گستردگی توابع Encoding/Decoding به گستردگی توابع هش کننده و یا حتی بیشتر از آن است. به عنوان مثال ASCII، Bas64، UTF16، UTF32 و ... همگی نمونه هایی از Encodingهای مختلف میباشند.
کاربردها:
اولین سوالی که ذهن با آن مواجه میشود این است که چرا باید Encodingهای مختلفی وجود داشته باشد؟
اگرچه دلایل زیادی برای به وجود آمدن انکدینگ های مختلف وجود دارد، اما دلیل اصلی آن عدم استاندارد سازی و استفاده از استانداردها در سالهای ابتدایی تولد نرم افزارها و سیستم عاملها و همچنین ایجاد قابلیت نمایش کاراکترهای خاص و کاراکترهای زبانهای مختلف است.
به عنوان مثال در ابتدا وقتی سیستم عاملها توسعه داده شدند، هر تولیدکننده ای بدون توجه به آنچه که تولیدکننده ی دیگر ارائه میدهد یک Encoding برای خود به وجود آورد! همچنین کسی در نظر نگرفته بود که حروف فارسی یا چینی یا زبان های دیگر و همچنین کاراکترهای خاص عبارت های ریاضی نیز قرار است در آن محصول استفاده شود و بنابرین بسنده کرده بودند به حروف انگلیسی کوچک و بزرگ و چند علامت سادهی ریاضی. از آنجا که تعداد این کاراکترها از تعداد حالت هایی که با 8 بیت میتوان تولید کرد افزون نبود، بنابرین 1 بایت را به آن اختصاص دادند و نام آن انکدینگ را ASCII گذاشتند. بعدها با گذر زمان وقتی نیاز به کاراکترهای بیشتر احساس شد، انکدینگ دیگری ارائه کردند که طول آن بیشتر از یک بایت باشد و بتواند کاراکترهای بیشتری در خود جای دهد. این روال در گذر زمان منجر شد که Encodingهای مختلفی بوجود آید. (مانند Unicode, UTF-32 و ...).
یکی دیگر از دلایل، ناسازگاری استانداردهای موجود برای انتقال بعضی داده ها و انجام بعضی کارها بود. به عنوان مثال استاندارد شده بود که برای جداسازی قسمت های مختلف یک URL (آدرس وب) از کاراکتر "/" استفاده شود. همچنین برنامه نویس میتوانست به گونه ای برنامه ی وب خود را بنویسد که پس از پر کردن یک فرم در صفحه توسط کاربر،محتویات آن فرم را از طریق Address-bar از وی دریافت کند.مشکلی که وجود داشت این بود که چنانچه کاربر در فرم خود از کاراکتر "/" استفاده میکرد، آنگاه حین ارسال این کاراکتر به سرور، به خاطد تداخل داده ی کاربر با کاراکتر جداکننده، با مشکل مواجه میشد. برای رفع این مسئله و چند مورد مشابه یک Encoding جدید به نام URL Encoding برای محتویات خط آدرس ارائه شد. در این سیستم جدید، کاراکترهای خاص نظیر / و فاصله و ' و " و ... پیش از ارسال به مقادیر دیگری تبدیل میشود (به ترتیب به 2F% و 20% و 27% و 22%) که با استاندارد آدرس دهی تداخلی نداشته باشند و آنگاه در سرور Decode شده و تفسیر میشوند.
انکدینگهای مشهور:
همانطور که در خلال متن اشاره شد، برای انکدینگ های مشهور میتوان به سری UTF اشاره کرد که شامل کاراکترهای زبان فارسی و ... میباشد ؛ ASCII که تنها شامل کاراکترهای زبان انگلیسی و یک سری کاراکتر خاص است و همچنین Base64 که معمولا برای نمایش خروجی توابع رمزنگاری استفاده می شود. برای تبدیل داده های خود از یک انکدینگ به انکدینگ دیگر میتوانید از ابزارهای آنلاین مانند این سایت استفاده کنید، یا این که با دانلود کردن نرم افزارهایی مثل ++Notepad از امکانات آنها برای تغییر Encoding بهره ببرید.
حتما تابحال با صحنه ی خرچنگ قورباغه بودن زیرنویس فارسی دانلود شده یا دریافت ایمیلی با محتوایی ناخوانا مواجه شده اید. منشاء این ناخوانا بودن و خرچنگ قورباغه بودن، عدم تطابق Encoding مبدا و مقصد است.(سازنده ی زیرنویس یا ایمیل با سیستم شما). در قسمت بعدی به روش های رفع این مشکل میپردازیم.
خوشا آنانکه الله یارشان بی
بحمد و قل هو الله کارشان بی
خوشا آنانکه دایم در نمازند
بهشت جاودان بازارشان بی

 Hamed
Hamed