پست قبلی: الگوریتم های سزار و اِنیگما
در پست های قبلی این مجموعه، ابتدا با الگوریتمهای درهمنگاری(Hash) و الگوریتمهای Encoding/Decoding آشنا شدیم، تفاوت آنها را با الگوریتم های رمزنگاری (Encryption/Decryption) بررسی کردیم و در نهایت پس از بررسی مقدمات توسعهی رمزنگاری و علل نیاز به آن، در این پست قرار است به تقسیمبندی های الگورتیم های رمزنگاری امروزی بپردازیم.
واژگان رمزنگاری:
پیش از آن که مشخصا به انواع تقسیم بندی بپردازیم، بد نیست که با یک مجموعه واژگان خاص این حوزه آشنا شویم.
- Plain Text: متن رمز نشده ای که قرار است برای رمزشدن به تابع Encryption وارد شود و همچنین متن رمزنشده ای از تابع Decryption بازگردانده میشود.
- Cipher Text: متن رمز شده ای که از تابع Encryption بازگردانده میشود و همچنین متن رمزشده ای که برای خارج شدن از رمز به تابع Decryption وارد میشود.
- Cipher: الگوریتمی که برای Encrypt یا Decrypt استفاده میشود. با این تعریف، در بعضی موارد از Encipher و Decipher به ترتیب به جای Encoding و Decoding استفاده میشود.
- Key: یک اطلاعات محرمانه که فقط و فقط فرستنده و گیرندهی پیام رمز شده از آن اطلاع دارند. Cipher از این کلید، برای انجام عملیات Encrypt و/یا Decrypt استفاده میکند.
- Cryptanalysis: به مطالعات و فعالیت هایی که روی یک الگوریتم رمزنگاری یا دادههای آن انجام میشود تا به واسطهی آنها امکان استخراج کلید رمزنگاری از داده های در دسترس یا امکان استخراج دادههای رمزنشده بدون داشتن کلید، بررسی شود. نام دیگر این فیلد Codebreaking میباشد.
- Salt, Nonce, Initial Vector: در پستهای بعدی!
و اما تقسیم بندی:
الگوریتمهای رمزنگاری را میتوان از چند بُعد تقسیمبندی کرد که مهمترین این ابعاد یکی تعداد کلیدهای لازم برای یکبار رمزکردن و خارج کردن از رمز و دیگری نوع پردازش شدن Plaintext در تابع Encrypt است.
- تقسیم بر اساس تعداد کلیدهای لازم:
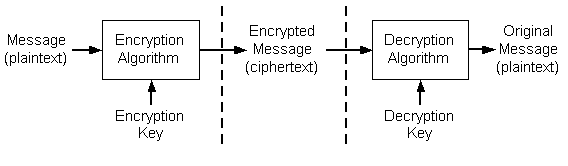
فرایند رمزکردن یک Plaintext و خارج کردن آن از رمز، روندی طبق شکل زیر دارد:
حال، با توجه به ماهیت الگوریتم، ممکن از مقدار Encryption Key با مقدار Decryption Key برابر باشد یا متفاوت از همدیگر باشند. الگوریتمهایی که مقدار این دو کلید با همدیگر یکسان است را Secret Key Algorithm یا Symmetric Algorithm یا Single Key Algorithm یا Conventional Algorithm الگوریتمهای متقارن مینامیم و الگوریتمهایی که در آنها مقدار کلیدها از همدیگر متمایز است را Public Key Algorithm یا Asymmetric Algorithm یا Two Key Algorithm یا الگوریتم های نامتقارن مینامیم. (از آنجا که روند کار الگوریتمهای نامتقارن ممکن است [به خاطر تفاوت کلیدها] در ذهن غیرممکن به نظر برسد، در پستهای بعدی احتمالا نمونه ای از این الگوریتمها را با هم به صورت جزییتر بررسی خواهیم کرد).
- تقسیم بر اساس نوع پردازش Plaintext:
در بعضی از الگوریتمهای رمزنگاری، طول پیامی که قرار است رمزشود، حتما باید مضرب صحیحی از یک عدد طبیعی خاص بزرگتر از یک باشد. به عنوان مثال طول پیام ورودی باید مضربی از 16 بایت باشد. به این نوع الگوریتمهای رمزنگاری، Block Cipher میگویند و آن عدد طبیعی خاص بزرگتر از یک Block Size نامیده میشود. مشخصا هنگامی که قرار است با استفاده از این نوع الگوریتمها پیامی را رمز کنیم که طول آن مضرب صحیحی از طول Block نیست، ناچاریم که تا رسیدن به طول لازم به آن داده اضافه کنیم. مکان و نوع دادهای که به پیام اضافه میشود میتواند دلخواه باشد، لیکن، برای سهولت امر و برای این که گیرندهی Ciphertext بتواند به سادگی پیام را از دادهی اضافه شده تمییز دهد، استانداردهای مختلفی ارائه شده است که خود به خود به انتهای پیام، مقداری را اضافه میکنند. به عمل اضافه کردن داده به پیام تا رسیدن به طول طول مجاز، Padding میگویند. در مقابل این نوع الگوریتمها، نوع دیگری از الگورتیمهای رمزنگاری را داریم که طول پیام هر مقدار دلخواهی میتواند باشد، به این نوع الگوریتمها که در اقلیت هستند، Stream Cipher میگویند.
مقایسه الگوریتمهای متقارن و نامتقارن:
ممکن این سوال برای خواننده پیش بیاید که کاربرد هر کدام از این دو نوع الگوریتم در چه مواقعی است و آیا مزیتی از نظر امنیتی به یکدیگر دارند؟
در پاسخ به این سوال ابتدا روند استفاده از الگوریتمهای نامتقارن را بررسی میکنیم. گفتیم که در الگوریتم های نامتقارن، Encryption Key و Decryption Key با هم متفاوتند. نام این کلیدها Public Key و Private Key است. پیامی که با یکی از این دو کلید رمزشود، فقط و فقط با کلید دیگر از رمز خارج میشود و استفاده از مقدار دیگری جز کلید دوم، منجر به دریافت دادههای چرند(:دی!) میشود. با توجه به این ساختار، هر موجودیتی باید یک جفت کلید برای خودش تولید کند و یکی را محرمانه نزد خود نگه دارد (Private Key) و دیگری را به شخصی که قصد دارد با اون ارتباط برقرار کند ارسال کند(Public Key).
برای روشن شدن فرآیند، تصویر زیر را مشاهده کنید:
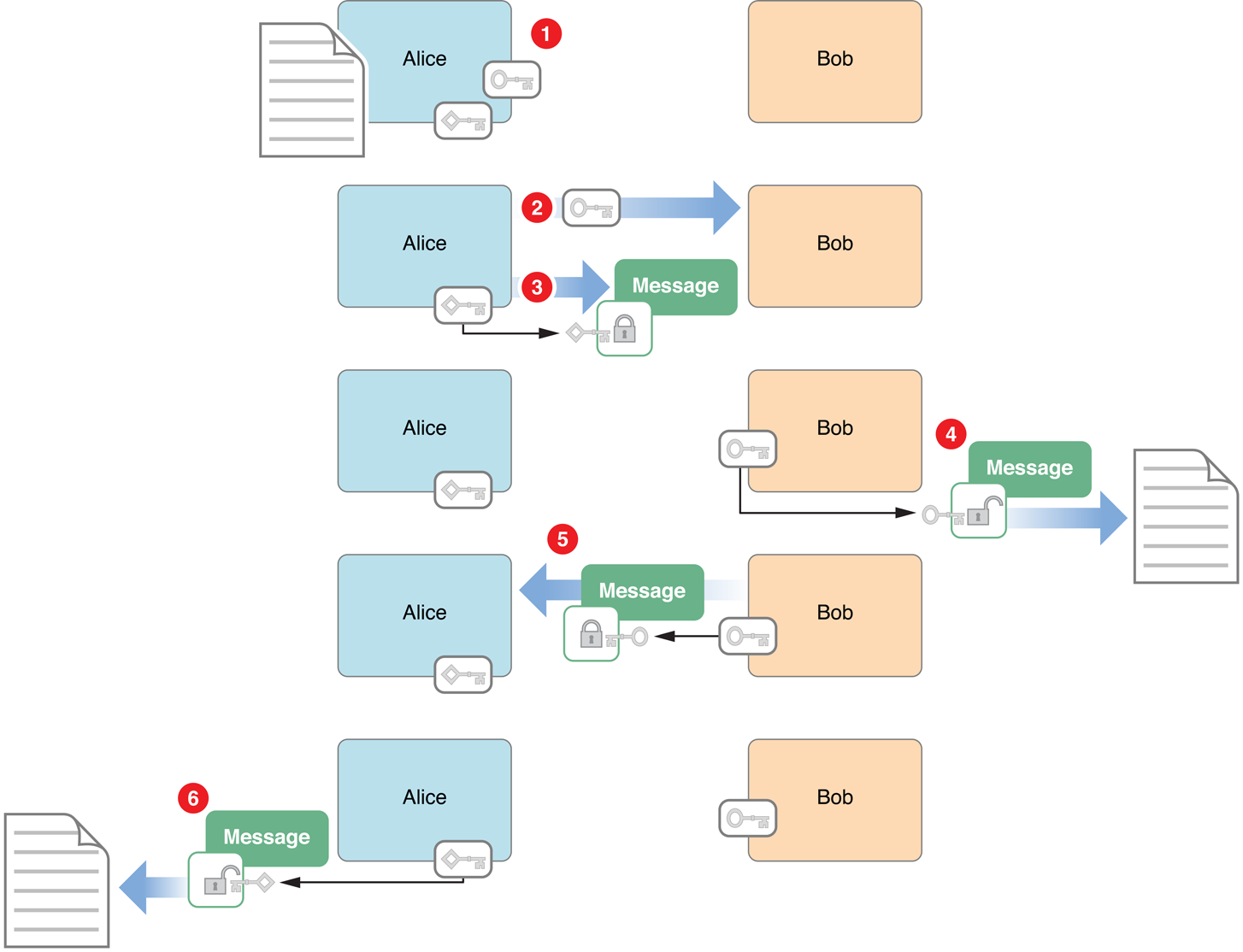
همانطور که در تصویر فوق میبینید، Alice در مرحلهی 1، یک جفت کلید تولید میکند و در مرحلهی 2، کلید عمومی خود را به Bob میدهد. سپس در مرحلهی 3، یک پیام که با کلید خصوصی خودش رمز شده است به باب ارسال میکند. از آنجا که این پیام با کلید خصوصی Alice رمز شده است، فقط و فقط با کلید عمومی او قابل رمزگشایی است[کلید عمومی را هر کسی میتواند با درخواست از Alice دریافت کند، بنابرین هر کسی میتواند این پیام را رمزگشایی کند]. Bob که کلید عمومی Alice را دارد، پیام او را از رمز خارج می کند، و در جواب به او، مجدد پیام خود را در مرحلهی 4 با کلید عمومی Alice رمز میکند. بدیهتا، از آنجا که پیام Bob با کلید عمومی Alice رمز شده است، تنها با کلید خصوصی Alice از رمز خارج میشود[و از آنجا که Alice کلید خصوصی اش را به هیچ کسی نمیدهد، فقط و فقط خودش قادر به رمزگشایی پیام Bob است]. در مرحلهی 6 هم Alice پیام Bob را با کلید خصوصی خودش از رمز خارج میکند.
دو نکته ای که باید متوجه آن شده باشید:
- برای این که یک ارتباط دو طرفهی کاملا امن بین Alice و Bob برقرار باشد، Bob هم باید یک جفت کلید تولید کند و کلید عمومی خودش را به Alice بدهد تا Alice به جای استفاده از کلید خصوصی خودش در مرحلهی 2، از کلید عمومی Bob استفاده کند(تا هیچکسی جز Bob قادر به رمزگشایی آن نباشد).
- برخلاف الگوریتمهای متقارن که در آنها لازم بود گیرنده و فرستنده از قبل به صورت مخفیانه با هم یک کلید را به اشتراک بگذارند، در الگوریتمهای نامتقارن، برای این که Alice و Bob بتوانند یک پیام محرمانه به همدیگر ارسال کنید، نیازی به اشتراک گذاشتن کلید به صورت مخفیانه نیست، بلکه به صورت کاملا واضح، کلیدهای عمومی خود را به همدیگر ارسال میکنند و کسی با استفاده از آنها نمیتواند به داده های رمزشده دست پیدا کند، زیرا در یک ساختار صحیح از Public Key تنها برای رمزکردن (Encrypt) و از Private Key تنها برای رمزگشایی (Decrypt) استفاده میشود.
تا اینجای کار، اینطور به نظر میرسد که الگوریتمهای نامتقارن به سبب نکتهی 2، از الگوریتمهای متقارن بهتر اند و باید استفاده از آنها را ترجیح داد. اما نکتهی دیگری که وجود دارد بار محاسباتی و زمانی است که پردازنده باید صرف پروسهی تولید کلید، رمزنگاری و رمزگشایی با الگوریتمهای این دو مجموعه بکند. در عمل، میانگین بار محاسباتی و زمان لازم برای پروسههایی با الگوریتم نامتقارن، بیشتر از پروسههای با الگوریتم متقارن است و از این منظر الگوریتمهای متقارن بر نامتقارنها ارجحیت دارند.
سوال: نهایتا کدام یک استفاده میشوند؟
جواب: هر دو! گذشته از این که ممکن است یک سیستم کلا استفاده از یکی را بر دیگری ترجیح دهد، روند متداول این است که ترکیبی از این دو استفاده میشود. به این صورت که در ابتدای ارتباط، از طریق الگوریتمهای نامتقارن یک کلید متقارن(Secret Key) را یکی به دیگری ارسال میکند و پس از ارسال این کلید، روند رمزنگاری ارتباط به الگورتیمهای متقارن Switch میکند. در واقع بعد از ارسال کلید متقارن که با رمزنگاری نامتقارن رمز شده است، مابقی ارتباط به صورت متقارن رمز میشود.
سوال: آیا صحیح است بگوییم الگوریتمهای نامتقارن از الگوریتمهای متقارن امنیت بیشتری دارند؟
جواب: خیر، امنیت یک الگوریتم رمزنگاری را ساختار الگورتیم آن (مشخص کننده ی زمان و تعداد کلیدهایی که باید امتحان شوند تا کلید رمزنگاری بدست آید)، طول کلید آن و نبود خطای منطقی(باگ) در الگوریتم آن تعیین میکنند. در واقع در صورتی که در ساختار یک الگوریتم متقارن و یک الگوریتم نامتقارن باگ وجود نداشته باشد، الگوریتمی امنیت بالاتری دارد که طول کلید آن بزرگتر باشد. از نگاه دیگر، همانقدر که محرمانه نگه داشتن Secret Key در الگوریتم متقارن اهمیت دارد، محرمانه نگه داشتن Private Key هم در الگوریتم نامتقارن اهمیت دارد. در این مورد در پست های بعدی توضیحات کاملتری خواهیم داشت.
اصولی در مورد الگوریتمهای رمزنگاری:
با گذشت زمان و پیدا شدن نقاط ضعف الگورتیمهای اولیه، رفته رفته اصولی برای الگوریتمهای رمزنگاری تدوین شد که در زیر به دو مورد اصلی آنها اشاره میکنیم:
- طول خروجی باید با طول ورودی الگوریتم برابر باشد (بر طبق اصل لانهی کبوتری، خروجی نمیتواند از ورودی کوتاه تر باشد. بلندتر بودن خروجی هم مزیتی ندارد و لازم نیست)
- فاش شدن الگوریتم نباید موجب شود Attacker بتواند دادههای رمز شده را رمزگشایی کند؛ و به عبارت دیگر باید تنها مبتنی بر محرمانه نگه داشتن کلید باشد. (یکی از اصول کرکهافس).
سوال: Security via Obscurity چیست؟
جواب: به مخفی نگه داشتن الگوریتم رمزنگاری به منظور افزایش امنیت (مثلا با کاهش احتمال پیدا شدن ایراد منطقی در الگوریتم)، Security by Obscurity گفته میشود.
الگوریتمهای رمزنگاری مشهور:
در زیر به چند مورد از الگوریتمهای رمزنگاری متقارن و نامتقارن مشهور اشاره شده است. لازم به ذکر است که کدام از این الگوریتمها میتوانند بر اساس طول کلید به زیر مجموعههایی تقسیم شوند. به عنوان مثال برای الگوریتم RSA زیر مجموعه های RSA-512, RSA-1024 .... RSA-4096 مرسوم هستند و برای الگوریتم AES سه زیر مجموعهی AES-192, AES-128و AES-256 را داریم (اندازهی بلاک در هر سه مورد 128 بیت است).
نامتقارن:
- RSA یا Rivest-Shamir-Adleman
- ECC یا Elliptic Curve Cryptography
- DH یا Diffie–Hellman
- ElGamal
متقارن:
- DES یا Data Encryption Standard
- TDES یا 3DES یا Triple DES
- AES یا Advanced Encryption Standrad
تا اینجای کار درک مطلوبی از اصطلاحات رمزنگاری و انواع الگوریتمها آن کسب کرده ایم، در قسمتهای بعدی سعی بر آن است که ابتدا با ماهیت امضای دیجیتال آشنا شویم و به صورت عملی با ابزارهای آنلاین و به صورت آفلاین با Libraryهای موجود داده ها را رمز، رمزگشایی و امضا کنیم.
قسمت بعدی: کاربرد و روند استفاده از امضای دیجیتال (به زودی)
بی مهری انسان معاصر در توست
تنهایی انسان نخستین در من ...
#میلاد_عرفان_پور
دنیای من برای دیدنِ دوبارهی یه دوست خیلی بزرگ و دست نیافتنی هست ولی برای دیدن دوبارهی آدمهای نچسب، خیلی خیلی کوچیک ...