خب، یکی از پیش نیازهایی که معمولا هم داخل برنامه نویسی، هم داخل کارهای مربوط به شبکه و امنیت و هم تو زمینه ی کار با کارت های هوشمند وجود داره، آشنایی با الگوریتمهای رمزنگاری هست. پیش از این که به صورت خاص به الگوریتم های رمزنگاری بپردازیم، لازمه که با یک سری اصطلاحات و واژگان مختلفی که تو این زمینه استفاده میشه و با هم جابجا گرفته میشه، آشنا بشیم و کاربردهای هر کدوم رو بشناسیم:
- هش کردن (Hashing)
- کد کردن / از کد خارج کردن (Encoding & Decoding)
- رمز کردن / از رمز خارج کردن (Encrypting & Decrypting)
قسمت 1: "هش کردن یا دَرهم نگاری"
معرفی فرایند:
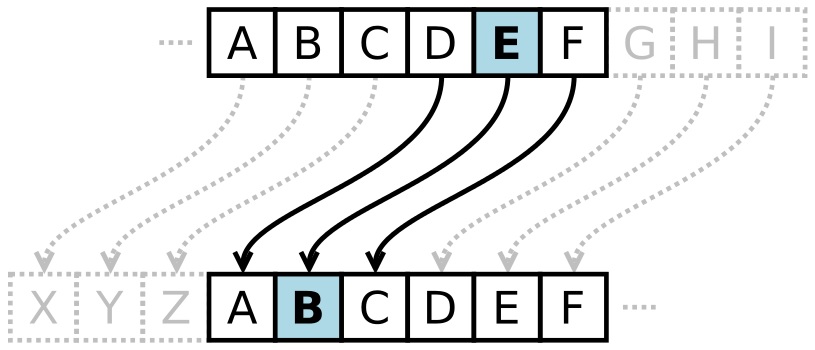
هش کردن، تولید یه متن از یه ورودی هست به نحوی که غیر قابل بازگشت باشه. یعنی از روی مقدار هَش، کسی نتونه داده ی اولیه رو بدست بیاره. چیزی که در مورد توابع درهم نگار (توابع هش کننده) باید بدونیم این هست که معمولا طول خروجی این توابع، مقدار ثابتی هست و این طول ثابت فارغ از طول ورودی است. سوال اولی که یه ذهن باهوش متوجه ش میشه این هست که بر این اساس، تابع های هش، توابع یک به یک نیستند. چرا که داشتن طول ثابت برای یه داده، به این معناست که تعداد حالت های محدودی میتونه داشته باشه (مثلا یه خروجی 4 بیتی، تعداد حالت هایی که میتونه داشته باشه 24 عدد است و ...)؛ در حالی که ورودی چون طول نامتناهی می تونه داشته باشه، پس تعداد حالت هاش هم نا متناهی میشه، و بنابر این، اختصاص مقادیر هش به مقادیر ورودی نمیتونه یک به یک باشه.
در جواب این سوال باید گفت که بله، نتیجه ی صحیحی گرفتید، به همین دلیل، توابع هش، یک به یک نیستند و هرچقدر که طول خروجی بزرگتر باشه، به یک-به-یک بودن نزدیک میشند(گرچه هیچ وقت نمیرسند!).
وقتی که قراره قدرت یه تابع/الگوریتم هَش کننده رو بررسی کنند، باید دو تا مسئله در نظر گرفته بشه:
- آیا با داشتن مقدار هَش یه داده، میتونیم داده رو بدست بیاریم؟
- آیا با داشتن یه مقدار هَش، میتونیم داده یا داده هایی تولید کنیم که با اون الگوریتم همین مقدار رو به ما بدهند؟
برای این که بتونیم تابع های هش رو حِس کنیم، من یه مثال فوق العاده ساده و قطعا فوق العاده ضعیف میزنم. فرض کنید که تابع هش ما به این صورت هست که یه رشته از ما میگیره و حروف جایگاه های فرد رو دور میریزه و از کنار هم گذاشتن پنج حرف اول مقادیر باقیمانده مقدار هش تولید میکنه. با این مثال ساده داریم:
Input 1: HelloMyDearFriend
Input 2: WhereDoYouWantToGO?
Step1 Of Hash(Input 1): -e-l-M-D-a-F-i-n-
Step1 Of Hash(Input 2): -h-r-D-Y-u-a-t-o-o
Final Hash(Input 1): elMDa
Final Hash(Input 2): hrDYu
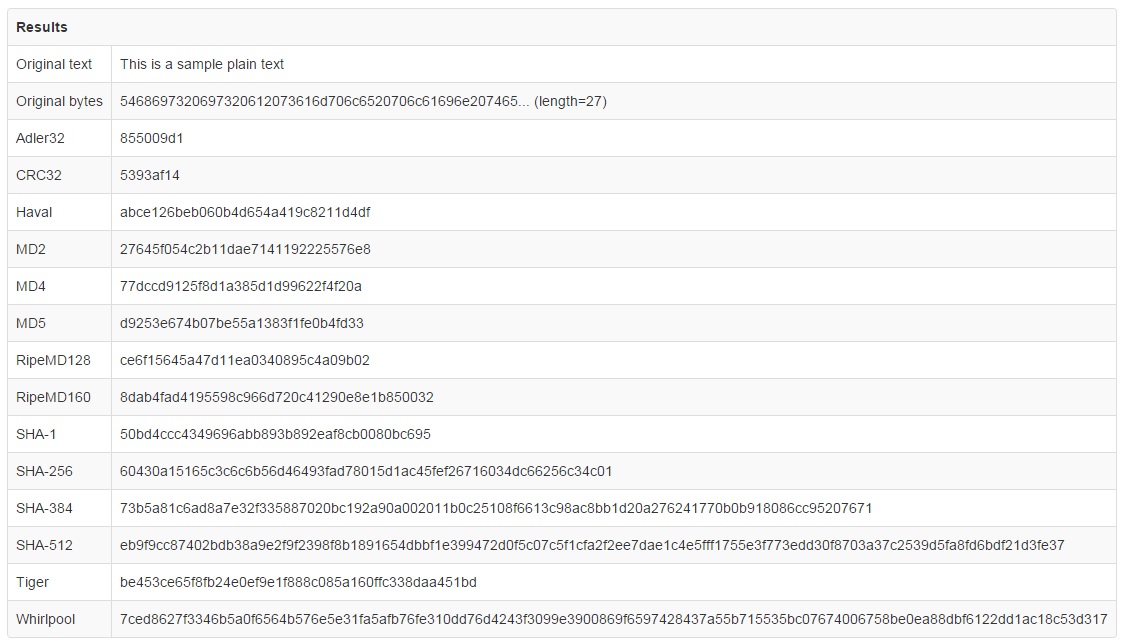
خب، همونطور که میبینیم، ما از ورودی های مختلف، خروجی های مختلفی به عنوان مقدار هَش شده بدست آوردیم که دیگه نمیتونیم مقدار اولیه رو از روی اون ها بدست بیاریم. ولی نکته ای که این الگوریتم داره اینه که، با داشتن مقدارهای هَش، خیلی ساده میتونیم داده ای بسازیم که بعد از پیاده سازی الگورتیم روی اون، همین خروجی تولید بشه. ضمنا بد نیست بدونیم که خروجی یک تابع هش رو Message Digest میگن.
کاربردها:
توابع هَش، دو تا کاربرد اصلی دارند:
- جایگزین پسورد برای ذخیره کردن در دیتابیس
- به عنوان Check Sum
اما هر کدوم از این ها چی هستند؟
جواب:
در مورد جایگزین پسورد برای دیتابیس: فرض کنید شما یه سایت راه اندازی کردید که برای دسترسی به یه قسمتی از سایت کاربرها باید اسم کاربری و کلمه ی عبور وارد کنند. خب، طبیعتا شما به عنوان مدیر سایت باید وقتی که کاربری قصد وارد شدن به سایت داره و نام کاربری و کلمه ی عبور خودش رو وارد میکنه، درست بودن این مقادیر رو بررسی کنید و تنها در صورت صحیح بودن، بهش اجازه ی ورود بدید. روش اولی که به ذهن میرسه اینه که، نام کاربری های مختلف رو با کلمه ی عبور مربوط به اونها داخل یه دیتابیس ذخیره کنید و هر بار مقادیر وارد شده رو با مقدارهای داخل دیتابیس مقایسه کنیم و الی آخر.
خب، این روش درسته؛ ولی یه ایراد امنیتی داره. اون هم این که، در صورتی که کسی تونست یه قسمتی از سایت ما رو هک کنه، یا حتی خیلی ساده سرور ما رو دزدید، به راحتی میتونه با باز کردن دیتابیس، همه ی نام کاربری ها و پسوردها رو ببینه و از اونجا که معمولا افراد برای سایت های مختلف کلمه های عبور یکسانی انتخاب میکنند، اطلاعات کاربر روی سایت های دیگه ای هم که عضوه، به خطر میفته.
خب کاربرد اول تابع های هَش اینجا خودش رو نشون میده. ما به عنوان برنامه نویس سایت، میایم به جای ذخیره کردن کلمه ی عبور، مقدار هَش شده ی اون رو داخل دیتا بیس ذخیره میکنیم. و از این به بعد هر بار که کاربر نام کاربری و کلمه ی عبور خودش رو وارد کرد، اول از کلمه ی عبور مقدار هَش رو بدست میاریم و بعد با مقدار داخل دیتابیس مقایسه میکنیم و الی آخر. با این مکانیزم، اگه سایت ما هک شد و کسی به نحوی به دیتابیس دست پیدا کرد، دیگه نمی تونه کلمه های عبور رو بدست بیاره.
و اما در مورد Checksum: فرض کنید شما قصد دارید فایلی رو روی سایت خودتون بذارید که کاربرهای شما دانلود کنند و میخواید اطمینان داشته باشید که فایلی که دانلود میکنند، داخل مسیر، به صورت اتفاقی(به خاطر Noise)و یا به صورت تعمدی(توسط یه هکر) دستکاری نشده باشه؛ خب چه راهکاری به ذهنتون میرسه؟
ساده ترین راهکار اینه که از محتویات فایل یه مقدار هش شده تولید کنید و این مقدار هش شده رو روی سایت قرار بدید. حالا کاربرهای شما وقتی فایل رو دانلود کردند، قبل از این که اجراش کنند، با همون تابع هش شما، از محتویات مقدار هَش رو تولید می کنند و با مقدار روی سایت مقایسه می کنند. در صورتی که هر دو مقدار با هم برابر بودند، نتیجه می گیرند فایل داخل مسیر عوض نشده.
الگوریتم های مشهور:
SHA - MD5 - NT - LM ....
توجه: بین hash و checksum و CRC علیرغم شباهت های زیاد، تفاوت هایی هم هست که برای اطلاع از اونها به ویکی پدیا مراجعه کنید. (:
احسان هنری نیست به امید تلافینیکی به کسی کن که به کار تو نیاید ...
#صائب